





Introduction to Web Scraping Python
Extracting information from webpages is known as ” Web Scraping Python.” You may use it to collect data that isn’t exposed via APIs or isn’t included in downloadable sets. Because of its ease of use and rich library support (like Beautiful Soup and Requests), Python is often used for this purpose.
Why Use Python for Web Scraping Python?
For the following reasons, Python is often cited as one of the finest languages for web scraping:
Ease of Use: Python’s clear and understandable syntax makes it beginner-friendly.
Abundance of Libraries: Python has a vast ecosystem of libraries for web scraping.
Community Support: Online materials and tutorials are in plenty.
Cross-Platform: Linux, macOS, and Windows all support Python.
Legality and Ethics
Understanding the ethical and legal issues is crucial before starting your web scraping adventure. Web scraping itself is not unlawful; however it may be against the law to take data from a website without authorization or in violation of its terms of service. Before scraping, always review a website’s robots.txt file and conditions of use.
Setting Up Your Environment
It’s necessary to set up your environment before you can begin web scraping in Python. the following steps:
Installing Python and Required Libraries
Install Python: Install Python if you don’t already have it by downloading it from the official Python website.
Install Beautiful Soup: The command to install Beautiful Soup is as follows:

Install Requests: Use the following command to install the Requests library:

Choosing the Right Development Environment
Choosing the right development environment is crucial for efficient web scraping. A Python package called Beautiful Soup makes it simple to extract data from HTML and XML texts. Let’s start with Beautiful Soup’s fundamentals.
Understanding HTML
HTML, the foundation of a web page, requires understanding its structure and navigation to effectively scrape data from it.
HTML Structure
HTML documents consist of tags, attributes, and content. A page’s structure is determined by tags, whereas element-specific characteristics provide further details. Content is what is shown on a page, including text, graphics, and links.
Inspecting Web Pages
The majority of online browsers have developer tools that let you examine a web page’s HTML. To see the HTML source code, do a right-click and choose “Inspect” on a website element. This is invaluable when identifying elements to scrape.
Getting Started with Beautiful Soup
A Python package called Beautiful Soup makes it simple to extract data from HTML and XML texts. Let’s start with Beautiful Soup’s fundamentals.
Introduction to Beautiful Soup
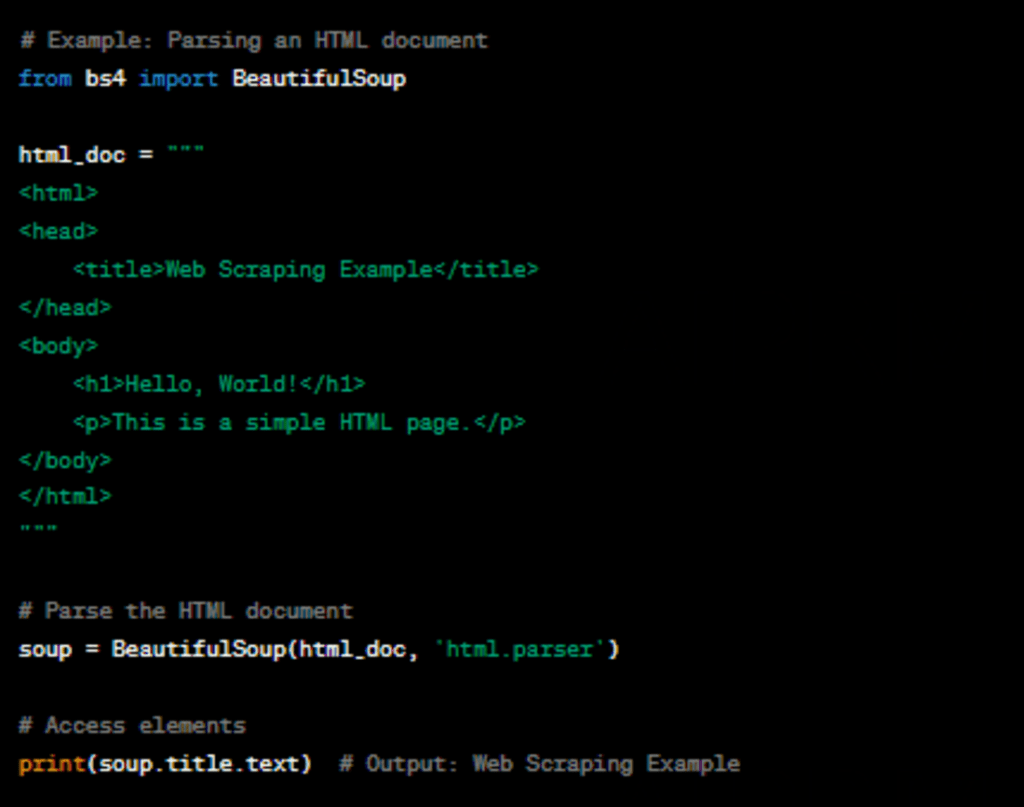
Beautiful Soup provides functions to parse HTML documents and navigate their structure. It creates a parse tree that you can search and manipulate to extract data.
Parsing HTML Documents
To start scraping, you need an HTML document to work with. You can either download an HTML page using Requests or work with a locally stored HTML file.
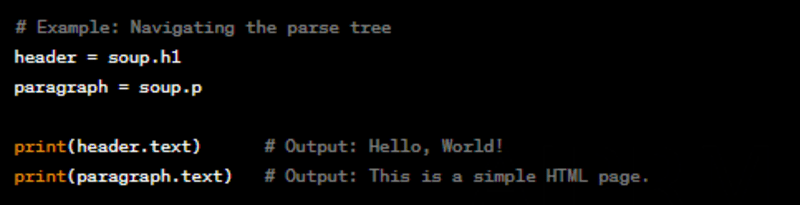
Navigating the Parse Tree
Once you have a parse tree, you can navigate it to find specific elements and their contents.
In the next section, we will explore how to use the Requests library to fetch web pages, setting the stage for real web scraping.
Using Requests to Fetch Web Pages
Before scraping a website, you need to retrieve its web pages. The Requests library simplifies the process of making HTTP requests.
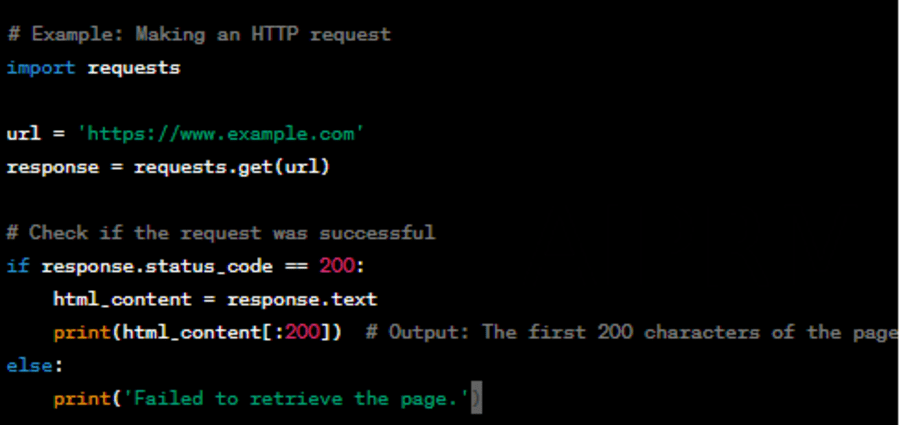
Making HTTP Requests
You utilize the requests to obtain a web page. Provide the URL of the page you want to see to the get() function.
Handling Cookies and Sessions
Some websites require cookies or sessions to access certain pages. You can use the Requests library to handle cookies and maintain sessions while scraping.
Dealing with Headers
Headers provide additional information in an HTTP request. You can customize headers to mimic the behavior of a web browser and avoid being detected as a bot.
In the upcoming sections, we will explore how to extract data from web pages using Beautiful Soup and Requests.
Scraping Data
Now that you understand the basics of HTML parsing and making HTTP requests, it’s time to delve into data scraping.
Extracting Text and Links
You can extract text and links from web pages using Beautiful Soup. For example, to extract all the links from a page:

Finding Elements by CSS Selectors
Beautiful Soup allows you to find elements using CSS selectors. This is especially useful for targeting specific elements on a page.

Handling Dynamic Content
Some websites load content dynamically using JavaScript. Beautiful Soup alone may not be sufficient in such cases. If you want to interact with the website, you may need to look at more complex methods or utilize programs like Selenium.
Preprocessing and data cleaning are crucial stages before saving the data that has been scraped, and they will be covered in the following section.
Data Cleaning and Preprocessing
Scraped data often requires cleaning and preprocessing to ensure its quality and usability.
Removing Unnecessary Characters
Scraped text may contain unnecessary characters like extra spaces, newlines, or HTML tags. You can clean the text using Python’s string manipulation functions.
Handling Missing Data
Web pages may have missing or incomplete data. You need to handle such cases gracefully to avoid errors in your analysis.
Data Validation
Data validation ensures that the scraped data meets your criteria for accuracy and completeness. Implement validation checks to identify and rectify anomalies.
In the following sections, we will explore how to store scraped data and delve into advanced web scraping techniques.
Storing Data
After scraping data, you need a way to store it for future use or analysis. Python offers various options for data storage.
Choosing the Right Data Storage Format
Choose a data storage format based on what you need. CSV, Excel, JSON, and databases like SQLite or PostgreSQL are examples of common formats.
Saving Data to CSV, Excel, and Databases
You can use libraries like Pandas for data manipulation and saving data to CSV or Excel files. For database storage, libraries like SQLAlchemy facilitate interaction with databases.
Data Serialization
Data serialization allows you to convert complex data structures into a format that can be easily stored and retrieved. Python’s pickle module is one option for serialization.
In the upcoming sections, we will explore advanced web scraping techniques and best practices.
Advanced Techniques
Web scraping can get complex when dealing with challenging websites. Here are some advanced techniques to tackle common obstacles.
Handling CAPTCHAs and Bot Detection
Some websites employ CAPTCHAs and bot detection mechanisms to deter scraping. You can use CAPTCHA solving services or rotate IP addresses to overcome these challenges.
Using Proxies
Proxies help you make requests from multiple IP addresses, reducing the risk of being blocked by a website. Proxy rotation can also be useful for scraping large amounts of data.
Scraping Multiple Pages and Sites
To gather extensive data, you may need to scrape multiple pages or websites. Implement pagination and crawling strategies to navigate through large datasets.
In the following sections, we will discuss best practices and ethical considerations in web scraping.
Web Scraping Best Practices
Web scraping, when done responsibly, benefits both individuals and organizations. Here are some best practices to follow:
Respecting Robots.txt
Check a website’s robots.txt file to understand which parts of the site are off-limits to crawlers. Respect these rules to maintain good scraping etiquette.
Avoiding Overloading Servers
Sending too many requests in a short time can overload a server and disrupt its operation. Implement rate limiting and throttling to avoid this.
Caching and Throttling
Implement caching mechanisms to store previously scraped data and reduce server load. Throttle your requests to maintain a reasonable pace.
Web Scraping Ethics
Web scraping should be conducted ethically and responsibly. Here are some ethical considerations:
Privacy Concerns
Avoid scraping personal or sensitive information without consent. Respect users’ privacy and adhere to data protection regulations.
Copyright and Fair Use
Respect copyright laws and fair use policies. Attribute content appropriately and avoid wholesale duplication.
Responsible Scraping
Be a responsible web scraper by minimizing the impact on websites. Avoid aggressive scraping that can disrupt their normal functioning.
In the next section, we will explore real-world applications of web scraping across different domains.
Conclusion
Web Scraping Python is a useful ability that provides access to a plethora of online data. Being able to collect and evaluate online data may be very beneficial for researchers, company owners, and data enthusiasts alike.
Continuous learning and adaptation are essential in the world of web scraping. As websites evolve, so should your scraping techniques. Remember to scrape responsibly, respecting the websites you visit and the data you collect.
Frequently Asked Questions
Is Web Scraping Python legal?
Web Scraping Python itself is not illegal, but it must be done responsibly and within the boundaries of the law. Always respect a website’s terms of service and robots.txt file.
What are the common challenges in Web Scraping Python?
Common challenges include handling website changes, anti-scraping measures, and debugging code when issues arise.
Can I scrape websites with dynamic content?
Yes, you can scrape websites with dynamic content, but it may require more advanced techniques and tools like Selenium.
What is the best data storage format for scraped data?
The choice of data storage format depends on your specific needs. Common formats include CSV, Excel, JSON, and databases like SQLite or PostgreSQL.
How can I prevent my scraping activities from being detected as a bot?
You can mimic human behavior by customizing your HTTP headers, using user-agent strings, and rotating IP addresses through proxies.
Read More: Techburneh.com




You helped me a lot with this post. I love the subject and I hope you continue to write excellent articles like this.
One Click Vids is a content genius! It’s revolutionized my YouTube and TikTok journey and turned affiliate promotions into a cash cow. Dive into this gem—it’s affordable and ridiculously user-friendly!